Getting Started with Managed ClickStack
The easiest way to get started is by deploying Managed ClickStack on ClickHouse Cloud, which provides a fully managed, secure backend while retaining complete control over ingestion, schema, and observability workflows. This removes the need to operate ClickHouse yourself and delivers a range of benefits:
- Automatic scaling of compute, independent of storage
- Low-cost and effectively unlimited retention based on object storage
- The ability to independently isolate read and write workloads with warehouses.
- Integrated authentication
- Automated backups
- Security and compliance features
- Seamless upgrades
Signup to ClickHouse Cloud
To create a Managed ClickStack service in ClickHouse Cloud first complete the first step of the ClickHouse Cloud quickstart guide.
We recommend this Scale tier for most ClickStack workloads. Choose the Enterprise tier if you require advanced security features such as SAML, CMEK, or HIPAA compliance. It also offers custom hardware profiles for very large ClickStack deployments. In these cases, we recommend contacting support.
Select the Cloud provider and region.
When specifying the select CPU and memory, estimate it based on your expected ClickStack ingestion throughput. The table below provides guidance for sizing these resources.
| Monthly ingest volume | Recommended compute |
|---|---|
| < 10 TB / month | 2 vCPU × 3 replicas |
| 10–50 TB / month | 4 vCPU × 3 replicas |
| 50–100 TB / month | 8 vCPU × 3 replicas |
| 100–500 TB / month | 30 vCPU × 3 replicas |
| 1 PB+ / month | 59 vCPU × 3 replicas |
These recommendations are based on the following assumptions:
- Data volume refers to uncompressed ingest volume per month and applies to both logs and traces.
- Query patterns are typical for observability use cases, with most queries targeting recent data, usually the last 24 hours.
- Ingestion is relatively uniform across the month. If you expect bursty traffic or spikes, you should provision additional headroom.
- Storage is handled separately via ClickHouse Cloud object storage and is not a limiting factor for retention. We assume data retained for longer periods is infrequently accessed.
More compute may be required for access patterns that regularly query longer time ranges, perform heavy aggregations, or support a high number of concurrent users.
Although two replicas can meet the CPU and memory requirements for a given ingestion throughput, we recommend using three replicas where possible to achieve the same total capacity and improve service redundancy.
These values are estimates only and should be used as an initial baseline. Actual requirements depend on query complexity, concurrency, retention policies, and variance in ingestion throughput. Always monitor resource usage and scale as needed.
Once you have specified the requirements, your Managed ClickStack service will take several minutes to provision. Feel free to explore the rest of the ClickHouse Cloud console whilst waiting for provisioning.
Once provisioning is complete, the 'ClickStack' option on the left menu will be enabled.
Setup ingestion
Once your service has been provisioned, ensure the the service is selected and click "ClickStack" from the left menu.

Select "Start Ingestion" and you'll be prompted to select an ingestion source. Managed ClickStack supports OpenTelemetry and Vector as its main ingestion sources. However, users are also free to send data directly to ClickHouse in their own schema using any of the ClickHouse Cloud support integrations.
Use of the OpenTelemetry is strongly recommended as the ingestion format. It provides the simplest and most optimized experience, with out-of-the-box schemas that are specifically designed to work efficiently with ClickStack.
- OpenTelemetry
- Vector
To send OpenTelemetry data to Managed ClickStack, you're recommended to use an OpenTelemetry Collector. The collector acts as a gateway that receives OpenTelemetry data from your applications (and other collectors) and forwards it to ClickHouse Cloud.
If you don't already have one running, start a collector using the steps below. If you have existing collectors, a configuration example is also provided.
Start a collector
The following assumes the recommended path of using the ClickStack distribution of the OpenTelemetry Collector, which includes additional processing and is optimized specifically for ClickHouse Cloud. If you're looking to use your own OpenTelemetry Collector, see "Configure existing collectors."
To get started quickly, copy and run the Docker command shown.

This command should include your connection credentials pre-populated.
While this command uses the default user to connect Managed ClickStack, you should create a dedicated user when going to production and modifying your configuration.
Running this single command starts the ClickStack collector with OTLP endpoints exposed on ports 4317 (gRPC) and 4318 (HTTP). If you already have OpenTelemetry instrumentation and agents, you can immediately begin sending telemetry data to these endpoints.
Configure existing collectors
It's also possible to configure your own existing OpenTelemetry Collectors or use your own distribution of the collector.
If you're using your own distribution, for example the contrib image, ensure that it includes the ClickHouse exporter.
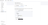
For this purpose, you're provided with an example OpenTelemetry Collector configuration that uses the ClickHouse exporter with appropriate settings and exposes OTLP receivers. This configuration matches the interfaces and behavior expected by the ClickStack distribution.
An example of this configuration is shown below (environment variables will be pre-populated if copying from the UI):
For further details on configuring OpenTelemetry collectors, see "Ingesting with OpenTelemetry."
Start ingestion (optional)
If you have existing applications or infrastructure to instrument with OpenTelemetry, navigate to the relevant guides linked from the UI.
To instrument your applications to collect traces and logs, use the supported language SDKs which send data to your OpenTelemetry Collector acting as a gateway for ingestion into Managed ClickStack.
Logs can be collected using OpenTelemetry Collectors running in agent mode, forwarding data to the same collector. For Kubernetes monitoring, follow the dedicated guide. For other integrations, see our quickstart guides.
Demo data
Alternatively, if you don't have existing data, try one of our sample datasets.
- Example dataset - Load an example dataset from our public demo. Diagnose a simple issue.
- Local files and metrics - Load local files and monitor the system on OSX or Linux using a local OTel collector.
Vector is a high-performance, vendor-neutral observability data pipeline, especially popular for log ingestion due to its flexibility and low resource footprint.
When using Vector with ClickStack, users are responsible for defining their own schemas. These schemas may follow OpenTelemetry conventions, but they can also be entirely custom, representing user-defined event structures.
The only strict requirement for Managed ClickStack, is that the data includes a timestamp column (or equivalent time field), which can be declared when configuring the data source in the ClickStack UI.
The following assumes you have an instance of Vector running, pre-configured with ingest pipelines, delivering data.
Create a database and table
Vector requires a table and schema to be defined prior to data ingestion.
First create a database. This can be done via the ClickHouse Cloud console.
For example, create a database for logs:
Then create a table whose schema matches the structure of your log data. The example below assumes a classic Nginx access log format:
Your table must align with the output schema produced by Vector. Adjust the schema as needed for your data, following the recommended schema best practices.
We strongly recommend understanding how Primary keys work in ClickHouse and choosing an ordering key based on your access patterns. See the ClickStack-specific guidance on choosing a primary key.
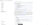
Once the table exists, copy the configuration snippet shown. Adjust the input to consume your existing pipelines, as well as the target table and database if required. Credentials should be pre-populated.
For more examples of ingesting data with Vector, see "Ingesting with Vector" or the Vector ClickHouse sink documentation for advanced options.
Navigate to the ClickStack UI
Select 'Launch ClickStack' to access the ClickStack UI (HyperDX). You will automatically authenticated and redirected.
- OpenTelemetry
- Vector
Data sources will be pre-created for any OpenTelemetry data.
If you are using Vector, you will need to create your own data sources. You will be prompted to create one on your first login. Below we show an example configuration for a logs data source.

This configuration assumes an Nginx-style schema with a time_local column used as the timestamp. This should be, where possible, the timestamp column declared in the primary key. This column is mandatory.
We also recommend updating the Default SELECT to explicitly define which columns are returned in the logs view. If additional fields are available, such as service name, log level, or a body column, these can also be configured. The timestamp display column can also be overridden if it differs from the column used in the table's primary key and configured above.
In the example above, a Body column does not exist in the data. Instead, it is defined using a SQL expression that reconstructs an Nginx log line from the available fields.
For other possible options, see the configuration reference.
Once created, you should be directed to the search view where you can immediately begin exploring your data.
And that’s it — you’re all set. 🎉
Go ahead and explore ClickStack: start searching logs and traces, see how logs, traces, and metrics correlate in real time, build dashboards, explore service maps, uncover event deltas and patterns, and set up alerts to stay ahead of issues.
Next Steps
If you have not recorded your default credentials during the above steps, navigate to the service and select Connect, recording the password and HTTP/native endpoints. Store these admin credentials securely, which can be reused in further guides.

To perform tasks such as provisioning new users or adding further data sources, see the deployment guide for Managed ClickStack.
